




distribution statistique (suite)
Distributions statistiques à un caractère
Des problèmes différents se posent suivant que le caractère étudié est qualitatif (attribut), avec des modalités mutuellement exclusives, ou quantitatif (variable discrète ou continue).
• Dans le cas d’un caractère qualitatif, le nombre de modalités étant en général petit, il s’agit d’un simple dénombrement ; cependant, celui-ci peut être long et fastidieux si la population étudiée est nombreuse, par exemple dans le cas du recensement, où l’on s’intéresse simultanément à plusieurs caractères de chaque individu. Les différentes modalités ayant été numérotées conformément à un code préfixé, et une carte perforée ayant été établie pour chacune des unités observées, le tri mécanique des unités suivant les diverses modalités, ainsi que leur dénombrement, peut être réalisé rapidement à l’aide d’une mécanographique ou d’un ordinateur ayant enregistré sur bandes magnétiques l’ensemble des informations recueillies sur chaque unité de la population. C’est ainsi, par exemple, qu’à partir des renseignements fournis par un recensement, on peut établir la distribution des individus suivant leur âge, leur état matrimonial, leur sexe, leur nationalité ou tout autre caractère, le tri mécanique permettant d’effectuer automatiquement les regroupements souhaités.
• Il en est de même dans le cas d’une variable discrète, ne pouvant prendre que des valeurs isolées, par exemple des valeurs entières successives : distribution des familles suivant le nombre d’enfants. Dans de tels cas, bien que le groupe observé fournisse une information complète sur la distribution, on est souvent amené à regrouper certaines valeurs de la variable correspondant à des effectifs trop petits pour avoir une signification dans la population dont provient l’échantillon observé (par sondage).
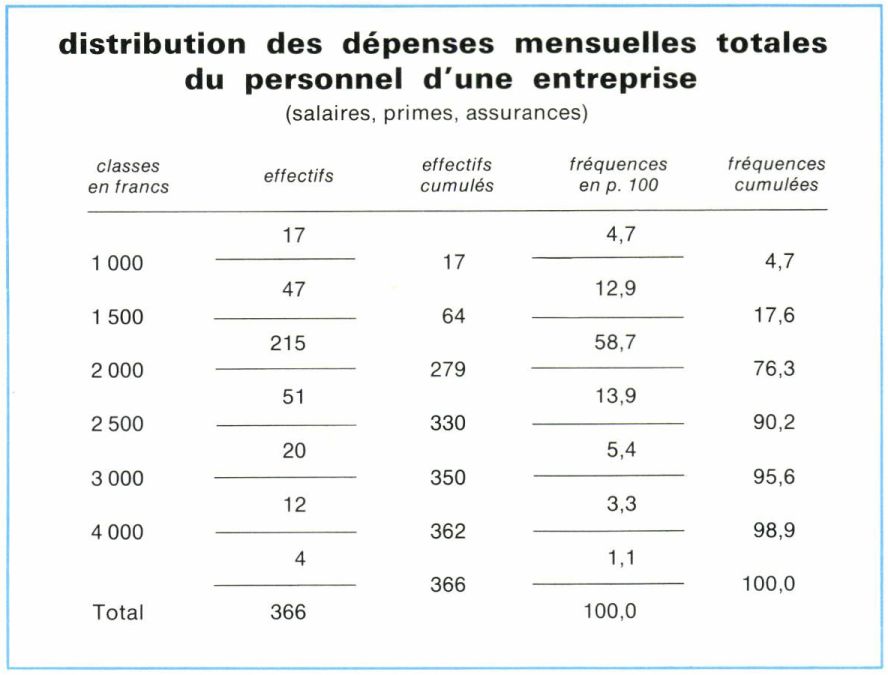
• Dans le cas d’une variable continue mesurable ou repérable (longueur, durée, température, etc.), compte tenu de la définition physique de la grandeur à mesurer, de la précision des mesures et aussi du souci de résumer les observations individuelles, tout en conservant une information suffisante sur l’ensemble, il est nécessaire de partager le domaine des variables observées en un certain nombre d’intervalles consécutifs, ou classes.
Une classe est définie soit par les limites de l’intervalle de classe, soit par une valeur caractéristique de cet intervalle, en général le centre de classe (moyenne arithmétique des limites), mais quelquefois par une seule des limites ; ainsi, par exemple, en démographie, la classe d’âge x comprend tous les individus dont l’âge est compris entre x et x + 1 années révolues. Les limites de classe doivent être précisées de manière que l’on sache dans quelle classe ranger une observation égale à l’une des limites, par exemple 20 à moins de 30, 30 à moins de 40, etc. Le choix des classes, qui, souvent, ne peut être fait que lorsque l’on a recueilli l’ensemble des informations individuelles, implique évidemment quelque arbitraire : on admet en général que 10 à 15 classes suffisent pour obtenir une présentation simple ne perdant pas trop d’informations. L’emploi de classes de même amplitude facilite les calculs ultérieurs aussi bien que les présentations graphiques, mais il ne convient pas pour des distributions dissymétriques très étalées vers les petites ou vers les grandes valeurs de la variable. Dans ce cas, il est souvent nécessaire d’utiliser des classes ouvertes n’ayant qu’une seule limite inférieure (ou supérieure) pour les grandes (ou les petites) valeurs de la variable.
Le choix des intervalles de classe étant arrêté, la répartition des observations dans les classes peut être faite en utilisant diverses méthodes : pointage des valeurs successives (comme clans le dépouillement des résultats d’une élection), emploi de machines à cartes perforées (trieuses) ou d’ordinateurs. À la distribution par classes, ainsi obtenue, on peut faire correspondre une distribution cumulée donnant le nombre total d’observations inférieures (ou supérieures) à chaque limite supérieure (ou inférieure) de classe. On peut aussi associer aux effectifs des classes ou aux effectifs cumulés les fréquences qui leur correspondent : quotients de ces effectifs par le nombre total des observations.
Caractéristiques numériques d’une distribution statistique à un caractère
Si l’on examine une distribution statistique, on constate souvent deux choses.
1. Les valeurs de la variable observée montrent une certaine tendance à être plus nombreuses dans une région particulière, souvent située vers le centre de la distribution (tendance centrale).
2. Autour de cette région centrale, les valeurs se répartissent de manière plus ou moins étalée (dispersion).
Ces deux éléments peuvent être caractérisés numériquement de manière, d’une part, à obtenir un résumé simplifié de l’ensemble de la distribution, et, d’autre part, à faciliter des comparaisons entre distributions de même nature relatives à des ensembles différents. Diverses caractéristiques numériques peuvent être envisagées. D’après G. Udney Yule (1871-1951), une caractéristique de tendance centrale ou de dispersion doit autant que possible satisfaire à certaines conditions :
1o être définie de façon objective, indépendante de l’observateur ;
2o avoir une signification concrète facile à interpréter ;
3o être simple à calculer par un utilisateur non familiarisé avec les calculs statistiques ;
4o dépendre de toutes les observations et non de certaines d’entre elles seulement ;
5o se prêter aisément aux calculs auxquels peut conduire son utilisation, par exemple dans l’étude du mélange de plusieurs distributions de même espèce observées séparément ;
6o être peu sensible aux fluctuations d’échantillonnage ; cette condition est fondamentale dans l’application de la méthode des sondages.
Distributions à plusieurs caractères
Si l’on considère simultanément, chez les n unités d’un échantillon, deux caractères qualitatifs ou mesurables A et B susceptibles de prendre diverses modalités ou valeurs A1, ..., Ai, ..., Ak et B1, ..., Bj, ..., Bh, la distribution dans cet échantillon est matérialisée par un tableau à double entrée donnant, pour chaque cas (Ai, Bj), le nombre nij des unités observées possédant simultanément les deux caractères Ai, et Bj. Dans le cas de variables continues X et Y, réparties individuellement en classes caractérisées par leurs centres xi, yj (distributions marginales), nij est le nombre des unités appartenant à la case (xi, yj).
À chaque modalité ou valeur de l’un des caractères ou de l’une des variables, X = xi par exemple, correspond une distribution de l’autre variable Y : distribution conditionnelle de Y pour X = xi ou distribution de Y liée par X = xi. Ces distributions pourront différer par leurs moyennes et par leurs variances.
Les distributions marginales ou conditionnelles sont des distributions à une variable qui peuvent être analysées individuellement.
Divers types de distributions à deux caractères peuvent être envisagés suivant la nature de chacun de ces deux caractères : qualitatifs, quantitatifs discrets, quantitatifs continus.