




communication (suite)
L’application du modèle à états finis à la concaténation des morphèmes suit les principes généraux définis précédemment. L’ensemble des morphèmes d’une langue naturelle représente le stock des éléments susceptibles de se combiner pour former des messages. Les restrictions sur l’ensemble des séquences théoriquement possibles (source de redondance) sont de nature syntaxique et opèrent sur des classes d’éléments qui peuvent prendre un certain nombre de positions dans la chaîne, à l’exclusion de toutes les autres. Ainsi, en français, il existe une contrainte très générale sur l’ordre des deux classes noms communs (Ncom) et articles (Art) : par exemple, avec les deux morphèmes « le » et « livre », la seule séquence admise est « le livre » ; en outre, si, à partir de l’état initial, le morphème de transition produit est « le », le Ncom suivant appartient obligatoirement à un sous-ensemble des Ncom comportant la caractéristique « masculin », à l’exclusion dé tous les Ncom caractérisés par le trait « féminin ». Dans l’état « le livre », il est théoriquement possible de calculer la probabilité de réalisation des classes suivantes (« verbe », ou « adjectif », ou certaines séquences de morphèmes comportant leurs propres règles combinatoires, telles les « propositions relatives »). Les relations entre les éléments sont analysées comme des systèmes de dépendances linéaires orientées de la gauche vers la droite, dans lesquels l’émission d’un élément est déterminée par l’ensemble des éléments précédemment émis. Cependant, les approximations obtenues dans la description des langues naturelles au moyen de ce modèle sont très insuffisantes au niveau syntaxique. Le modèle théorique de type markovien ne peut rendre compte de manière simple et réellement adéquate des principaux phénomènes linguistiques. Outre le grand nombre des unités morphématiques et leur relative instabilité, Noam Chomsky* a démontré que les contraintes syntaxiques dans les langues naturelles possèdent des propriétés particulières telles que la récursivité non bornée et non nécessairement orientée de gauche à droite, donc la possibilité de récursivité par système d’auto-enchâssement, qui font des langues naturelles des langages à nombre infini d’états ; celles-ci ne peuvent donc pas être adéquatement décrites à partir du modèle des processus de Markov. Dans la seule perspective linguistique, outre les applications importantes du modèle informationnel en traduction automatique et en psycholinguistique, les études entreprises par les théoriciens de la communication ont permis d’éclairer les fondements théoriques et mathématiques de l’analyse distributionnelle, en marquant du même coup ses limites (particulièrement en syntaxe) ; ces études ont permis aussi de préciser les rapports qu’entretient la linguistique avec certaines branches des mathématiques. De ces rapports sont issues de nouvelles recherches, réunies sous le nom de linguistique mathématique ou grammaire formelle, fondées non plus sur un modèle « probabiliste et informationnel », mais sur les types d’opérations logico-mathématiques abstraites mises en œuvre dans des « langages » de complexité croissante ; les langues naturelles n’étant, dans cette conception, que l’exemple le plus achevé, et non résolu, de cette complexité.
Linguistique et statistique
Les hypothèses envisagées par les théoriciens de la communication concernant la transmission de l’information au moyen des langues naturelles font appel à des données statistiques précises permettant d’attribuer une certaine probabilité aux différents éléments. L’utilisation de notions statistiques très élémentaires est courante en linguistique depuis fort longtemps ; ainsi, la constitution d’un dictionnaire dont une unité est définie par une « moyenne » des emplois les plus courants, ou en grammaire les listes d’exceptions. Mais l’application en linguistique de méthodes statistiques précises ne date que des années 1925-1930. Elle est l’œuvre du linguiste américain George Kingsley Zipf. Ses observations vérifient certaines des hypothèses faites par les linguistes « fonctionnalistes » (école de Prague) : les phonèmes qui ont peu de « rendement fonctionnel », c’est-à-dire dont le système d’opposition est limité (par exemple en français les oppositions [a] - [α] ou 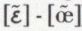 ), ont une fréquence très basse et tendent à disparaître ; les unités les plus complexes sont moins fréquentes que les autres ; ainsi, dans les langues qui connaissent l’opposition sourde-sonore, les premières sont plus fréquentes que les secondes ; en outre, si une unité complexe devient plus fréquente dans son emploi, elle tend à se simplifier (en entraînant des modifications sensibles sur l’ensemble du système phonologique considéré). Cependant, l’aspect le plus connu et le plus original de l’œuvre de G. K. Zipf concerne l’application des méthodes statistiques au niveau du « vocabulaire » d’un texte. Les variables enregistrées ne sont plus les phonèmes (ou les lettres), mais les mots, définis comme l’espace compris entre deux blancs graphiques. Avec un texte assez long, on constate certaines régularités distributionnelles, dont une des plus importantes est connue sous le nom de loi de Zipf : si l’on classe les différents mots du texte par rang de fréquence décroissante, le produit du rang par la fréquence est constant, c’est-à-dire que la fréquence d’un mot est inversement proportionnelle à son rang. Les différentes études statistiques faites par Zipf sur des textes de Joyce, Plaute, Homère... ont été vérifiées pour d’autres langues, démontrant la validité générale de l’équation f × r = C, avec certaines modifications précisées par Benoît Mandelbrot concernant les fréquences les plus hautes et les plus basses. De plus, G. K. Zipf constatait qu’il existe un rapport relativement constant entre la longueur d’une unité (son nombre de lettres) et sa fréquence ; et, d’autre part, entre le nombre de ses acceptions sémantiques (enregistrées dans les dictionnaires) et sa fréquence. Cet ensemble de faits statistiques conduisait G. K. Zipf à proposer une hypothèse linguistique fondée sur l’équilibre entre deux tendances contraires apparaissant dans le système de communication linguistique : la tendance à la spécification minimale, parce que moins « coûteuse en énergie » (du point de vue du locuteur), et la tendance à la spécification maximale, ne permettant pas d’ambiguïté sur le message (du point de vue du récepteur). Cette hypothèse avait déjà été émise par Otto Jespersen, qui voyait dans les langues un progrès tendant à obtenir « le maximum d’efficacité en utilisant le minimum de moyens » ; de même, elle est à la base de l’« économie dans le langage », dans l’œuvre d’André Martinet. Quelle que soit l’interprétation strictement linguistique donnée aux lois de Zipf, il semble que la loi f × r = C soit beaucoup plus générale que ne l’avait supposé G. K. Zipf lui-même. En effet, B. Mandelbrot et Pierre Guiraud ont montré que des ensembles d’éléments différents des éléments linguistiques présentent les caractéristiques distributionnelles régulières dégagées par la loi de Zipf. Actuellement, les études statistiques poursuivies sur les « textes » concernent le plus souvent des recherches stylistiques, permettant de comparer les textes d’un même auteur ou de différents auteurs entre eux, ou encore les fréquences relatives de certains éléments chez un auteur par rapport à la fréquence absolue des mêmes éléments dans la langue à la même époque. Les « écarts » manifestés sont considérés comme significatifs de certaines tendances, interprétables en termes littéraires, historiques, sociologiques selon les différentes hypothèses ayant présidé aux études statistiques.
), ont une fréquence très basse et tendent à disparaître ; les unités les plus complexes sont moins fréquentes que les autres ; ainsi, dans les langues qui connaissent l’opposition sourde-sonore, les premières sont plus fréquentes que les secondes ; en outre, si une unité complexe devient plus fréquente dans son emploi, elle tend à se simplifier (en entraînant des modifications sensibles sur l’ensemble du système phonologique considéré). Cependant, l’aspect le plus connu et le plus original de l’œuvre de G. K. Zipf concerne l’application des méthodes statistiques au niveau du « vocabulaire » d’un texte. Les variables enregistrées ne sont plus les phonèmes (ou les lettres), mais les mots, définis comme l’espace compris entre deux blancs graphiques. Avec un texte assez long, on constate certaines régularités distributionnelles, dont une des plus importantes est connue sous le nom de loi de Zipf : si l’on classe les différents mots du texte par rang de fréquence décroissante, le produit du rang par la fréquence est constant, c’est-à-dire que la fréquence d’un mot est inversement proportionnelle à son rang. Les différentes études statistiques faites par Zipf sur des textes de Joyce, Plaute, Homère... ont été vérifiées pour d’autres langues, démontrant la validité générale de l’équation f × r = C, avec certaines modifications précisées par Benoît Mandelbrot concernant les fréquences les plus hautes et les plus basses. De plus, G. K. Zipf constatait qu’il existe un rapport relativement constant entre la longueur d’une unité (son nombre de lettres) et sa fréquence ; et, d’autre part, entre le nombre de ses acceptions sémantiques (enregistrées dans les dictionnaires) et sa fréquence. Cet ensemble de faits statistiques conduisait G. K. Zipf à proposer une hypothèse linguistique fondée sur l’équilibre entre deux tendances contraires apparaissant dans le système de communication linguistique : la tendance à la spécification minimale, parce que moins « coûteuse en énergie » (du point de vue du locuteur), et la tendance à la spécification maximale, ne permettant pas d’ambiguïté sur le message (du point de vue du récepteur). Cette hypothèse avait déjà été émise par Otto Jespersen, qui voyait dans les langues un progrès tendant à obtenir « le maximum d’efficacité en utilisant le minimum de moyens » ; de même, elle est à la base de l’« économie dans le langage », dans l’œuvre d’André Martinet. Quelle que soit l’interprétation strictement linguistique donnée aux lois de Zipf, il semble que la loi f × r = C soit beaucoup plus générale que ne l’avait supposé G. K. Zipf lui-même. En effet, B. Mandelbrot et Pierre Guiraud ont montré que des ensembles d’éléments différents des éléments linguistiques présentent les caractéristiques distributionnelles régulières dégagées par la loi de Zipf. Actuellement, les études statistiques poursuivies sur les « textes » concernent le plus souvent des recherches stylistiques, permettant de comparer les textes d’un même auteur ou de différents auteurs entre eux, ou encore les fréquences relatives de certains éléments chez un auteur par rapport à la fréquence absolue des mêmes éléments dans la langue à la même époque. Les « écarts » manifestés sont considérés comme significatifs de certaines tendances, interprétables en termes littéraires, historiques, sociologiques selon les différentes hypothèses ayant présidé aux études statistiques.
G. P.
➙ Cybernétique / Information / Modèle.